基于Python的携程出行产品未来14个月销量预测 数据处理流程与实践
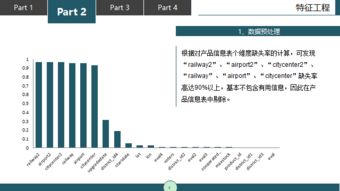
基于Python的携程出行产品未来14个月销量预测:数据处理流程与实践
在旅游行业,准确预测出行产品的未来销量对于库存管理、营销策略制定和收益优化至关重要。本文将以携程出行产品(如机票、酒店、度假套餐等)为例,详细介绍如何使用Python进行数据预处理、特征工程和初步分析,为后续构建销量预测模型奠定坚实的数据基础。预测未来14个月的销量属于中长期时间序列预测,对数据的完整性和质量要求极高。
一、 数据获取与理解
我们需要获取历史销售数据。数据可能来源于公司数据库、数据仓库或提供的CSV/Excel文件。典型的数据字段包括:
- 产品标识:产品ID、名称、类别(机票/酒店/跟团游等)。
- 时间维度:订单日期、出行日期(对于预订类产品尤为重要)。
- 销售指标:销量(订单数)、销售额、预订量。
- 产品属性:出发城市、目的地城市、价格、舱等/房型、是否促销。
- 外部因素:节假日标记、天气数据(可能需要后期整合)、宏观经济指标。
使用pandas库进行初步加载和探索:`python
import pandas as pd
import numpy as np
df = pd.readcsv('ctripsalesdata.csv', parsedates=['orderdate', 'traveldate'])
print(df.head())
print(df.info())
print(df.describe())`
二、 数据清洗与预处理
这是确保预测准确性的核心步骤。
1. 处理缺失值:检查并处理销量等关键字段的缺失。
`python
# 检查缺失
print(df.isnull().sum())
# 根据情况填充或删除。例如,对销量缺失,若为近期数据可置0,或使用前后均值/插值法填充。
df['sales_volume'].fillna(method='ffill', inplace=True) # 前向填充,需谨慎
`
2. 处理异常值:销量可能因系统错误、大型团购等出现极端值。
`python
# 使用IQR或标准差方法检测
Q1 = df['salesvolume'].quantile(0.25)
Q3 = df['salesvolume'].quantile(0.75)
IQR = Q3 - Q1
lowerbound = Q1 - 1.5 * IQR
upperbound = Q3 + 1.5 * IQR
# 可以考虑用边界值替换或视为缺失值处理
df['salesvolume'] = np.where(df['salesvolume'] > upperbound, upperbound, df['sales_volume'])
`
- 数据一致性检查:确保日期格式正确,价格非负,出行日期晚于订单日期等。
三、 特征工程
为时间序列预测模型构建有效的特征是关键。
1. 时间特征提取:从订单/出行日期中提取丰富的时序特征。
`python
df['year'] = df['orderdate'].dt.year
df['month'] = df['orderdate'].dt.month
df['dayofmonth'] = df['orderdate'].dt.day
df['dayofweek'] = df['orderdate'].dt.dayofweek # 周一=0
df['weekofyear'] = df['orderdate'].dt.isocalendar().week
df['isweekend'] = df['dayofweek'].apply(lambda x: 1 if x >= 5 else 0)
`
2. 滞后特征:历史销量对未来预测有直接影响。由于预测未来14个月,我们需要创建过去多个时间窗口的滞后特征。
`python
# 假设数据已按产品和日期排序
for lag in [1, 3, 6, 12]: # 滞后1个月、3个月、半年、一年
df[f'saleslag{lag}m'] = df.groupby('productid')['salesvolume'].shift(lag * 30) # 简化为30天一个月
`
3. 滚动统计特征:捕捉趋势和季节性。
`python
df['rollingmean3m'] = df.groupby('productid')['salesvolume'].transform(lambda x: x.rolling(window=90, minperiods=1).mean())
df['rollingstd3m'] = df.groupby('productid')['salesvolume'].transform(lambda x: x.rolling(window=90, minperiods=1).std())
`
- 节假日与事件特征:整合中国的法定节假日、寒暑假、旅游旺季(如国庆、春节)作为二元特征或影响权重。
5. 产品类别编码:对出发地、目的地、产品类型等进行标签编码或独热编码。
`python
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
df['departurecityencoded'] = le.fittransform(df['departurecity'])
# 或者使用pd.get_dummies进行独热编码
df = pd.getdummies(df, columns=['producttype'], prefix='type')
`
四、 数据重构与聚合
预测目标通常是未来14个月每个月的总销量。因此,我们需要将原始数据(可能是日度或周度)聚合到月度级别。
`python
# 假设以‘order_date’的月份为时间点进行聚合,并计算月度销量
monthlydf = df.setindex('orderdate').groupby(['productid', pd.Grouper(freq='M')])['salesvolume'].sum().resetindex()
# 确保时间序列连续,填充可能缺失的月份(销量为0)
创建完整的日期范围
alldates = pd.daterange(start=monthlydf['orderdate'].min(), end=monthlydf['orderdate'].max(), freq='M')
allproducts = monthlydf['product_id'].unique()
# 使用交叉连接创建完整面板数据
fullindex = pd.MultiIndex.fromproduct([allproducts, alldates], names=['productid', 'orderdate'])
monthlydffull = monthlydf.setindex(['productid', 'orderdate']).reindex(fullindex, fillvalue=0).reset_index()`
五、 为预测准备数据集
将处理好的数据划分为训练集和测试集。由于是时间序列,不能随机划分,必须按时间顺序划分。
`python
# 假设我们最后14个月作为验证未来预测的参考,倒数第15个月之前的数据用于训练
cutoffdate = monthlydffull['orderdate'].max() - pd.DateOffset(months=14)
traindata = monthlydffull[monthlydffull['orderdate'] < cutoff_date]
# 注意:实际预测时,我们使用全部历史数据训练,然后预测未来14个月。
这里的划分是为了验证模型在“已知未来”一段时期上的表现。
`
六、 数据标准化/归一化
对于涉及距离的模型(如神经网络、SVM),需要对数值特征进行缩放。对于树模型(如LightGBM, XGBoost)通常不需要。
`python
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
numericalfeatures = ['price', 'rollingmean3m', 'saleslag_12m'] # 示例特征列
scaler.fit(traindata[numericalfeatures])
traindata[numericalfeatures] = scaler.transform(traindata[numericalfeatures])
# 对测试数据使用相同的scaler进行转换
`
###
通过以上步骤,我们完成了携程出行产品销量预测项目的数据处理阶段。我们清洗了原始数据,构建了包含时序滞后、滚动统计、节假日等多维特征的数据集,并将其规范化为适合机器学习模型输入的格式。处理后的数据将作为输入,用于训练如Prophet、ARIMA、LightGBM或LSTM等时间序列预测模型,以生成未来14个月的销量预测。值得注意的是,在实际项目中,数据处理是一个迭代过程,需要根据模型反馈不断调整特征工程策略,并与业务理解紧密结合,才能获得具有指导意义的预测结果。
如若转载,请注明出处:http://www.tobeonetop.com/product/86.html
更新时间:2026-06-18 23:12:38